BloomFilter概念及原理
布隆过滤器(英语:Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。主要用于判断一个元素是否在一个集合中。
布隆过滤器的原理是,当⼀个元素被加⼊集合时,通过K个散列函数将这个元素映射成⼀个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(⼤约)知道集合中有没有它了:如果这些点有任何⼀个0,则被检元素⼀定不在;如果都是1,则被检元素很可能在。 如下图所示:
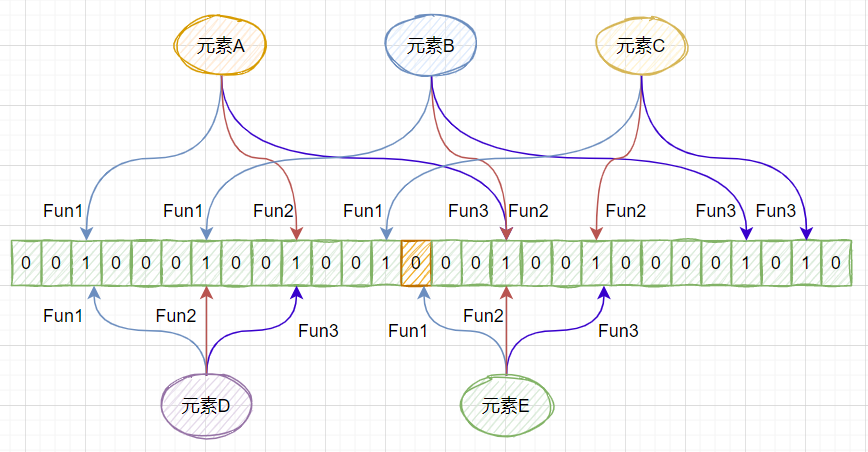
比如:我们现在把元素 A、B、C加载到布隆过滤器中,每个元素经过3个散列函数映射到不同的位置,并将该位置置为1,如果我们判断元素D、发现它映射之后的位置都是1,但是我们不能判断元素D一定存在,因为该位置的1并不是由元素D置为的1,这就是布隆过滤器的误判,是由于哈希冲突造成的,反之我们看元素E,它映射之后有一个位置是0,那么说明元素E一定不存在,这就是布隆过滤器的基本原理。
总结来说就是下面两句话:
- 如果元素映射之后的位置有任何一个是0,那么该元素一定不存在
- 如果都是1,则该元素可能存在
上面说的是布隆过滤器的添加和查询操作,那如果我们想删除一个元素呢?
由于布隆过滤器的每一个 bit 并不是独占的,很有可能多个元素共享了某一位,如果我们直接删除这一位的话,就会影响到其他的元素。
布隆过滤器的优点:
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数O(K)级别的,其次,布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
布隆过滤器的缺点:
存在误判,可能该元素并不存在,但是该元素映射之后的所有位都是1。再就是删除元素困难,可能会影响其他的元素。
布隆过滤器的使用场景及实现
布隆过滤器的典型应用有:
- 缓存穿透问题,过滤掉不存在的数据,阻止请求打到数据库上使数据库宕机。
- WEB拦截器,如果相同请求则拦截,防止重复被攻击。
- ……
自定义一个 BloomFilter
public class MyBloomFilter {
// 一个长度为10 亿的比特位
private static final int DEFAULT_SIZE = 256 << 22;
// 为了降低错误率,使用加法hash算法,所以定义一个8个元素的质数数组
private static final int[] seeds = {3, 5, 7, 11, 13, 31, 37, 61};
// 相当于构建 8 个不同的hash算法
private static HashFunction[] functions = new HashFunction[seeds.length];
// 初始化布隆过滤器的 bitmap
private static BitSet bitset = new BitSet(DEFAULT_SIZE);
/**
* 添加数据
* @param value 需要加入的值
*/
public static void add(String value) {
if (value != null) {
for (HashFunction f : functions) {
//计算 hash 值并修改 bitmap 中相应位置为 true
bitset.set(f.hash(value), true);
}
}
}
/**
* 判断相应元素是否存在
* @param value 需要判断的元素
* @return 结果
*/
public static boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (HashFunction f : functions) {
ret = bitset.get(f.hash(value));
//一个 hash 函数返回 false 则跳出循环
if (!ret) {
break;
}
}
return ret;
}
/**
* 模拟用户是不是会员,或用户在不在线。。。
*/
public static void main(String[] args) {
for (int i = 0; i < seeds.length; i++) {
functions[i] = new HashFunction(DEFAULT_SIZE, seeds[i]);
}
// 添加1亿数据
for (int i = 0; i < 100000000; i++) {
add(String.valueOf(i));
}
String id = "123456789";
add(id);
System.out.println(contains(id)); // true
System.out.println("" + contains("234567890")); //false
}
}
class HashFunction {
private int size;
private int seed;
public HashFunction(int size, int seed) {
this.size = size;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
int r = (size - 1) & result;
return (size - 1) & result;
}
}好啦,我们自定义的 BloomFilter 就完成了,下面我们来看看一些第三方的 BloomFilter 的实现吧。
Guava 中的 BloomFilter
引入依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>public class GuavaBloomFilterDemo {
public static void main(String[] args) {
//后边两个参数:预计包含的数据量,和允许的误差值
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 100000, 0.01);
for (int i = 0; i < 100000; i++) {
bloomFilter.put(i);
}
System.out.println(bloomFilter.mightContain(1));
System.out.println(bloomFilter.mightContain(2));
System.out.println(bloomFilter.mightContain(3));
System.out.println(bloomFilter.mightContain(100001));
//bloomFilter.writeTo();
}
}Redis 中的 BloomFilter
Redis 提供的 bitMap 可以实现布隆过滤器,但是需要自己设计映射函数和一些细节,这和我们自定义没啥区别。
Redis 官方提供的布隆过滤器到了 Redis 4.0 提供了插件功能之后才正式登场。布隆过滤器作为一个插件加载到 Redis Server 中,给 Redis 提供了强大的布隆去重功能。
使用:
布隆过滤器基本指令:
- bf.add 添加元素到布隆过滤器
- bf.exists 判断元素是否在布隆过滤器
- bf.madd 添加多个元素到布隆过滤器,bf.add 只能添加一个
- bf.mexists 判断多个元素是否在布隆过滤器
127.0.0.1:6379> bf.add user Tom
(integer) 1
127.0.0.1:6379> bf.add user John
(integer) 1
127.0.0.1:6379> bf.exists user Tom
(integer) 1
127.0.0.1:6379> bf.exists user Linda
(integer) 0
127.0.0.1:6379> bf.madd user Barry Jerry Mars
1) (integer) 1
2) (integer) 1
3) (integer) 1
127.0.0.1:6379> bf.mexists user Barry Linda
1) (integer) 1
2) (integer) 0我们只有这几个参数,肯定不会有误判,当元素逐渐增多时,就会有一定的误判了,这里就不做这个实验了。关于 Redis 中布隆过滤器更多的知识小伙伴们可以自己去了解。



