吊打面试官之 Hashtable 详解
如何保证 HashMap 线程安全
我们知道 HashMap 是线程不安全的,我们一般使用这三种方式来代替原生的线程不安全的 HashMap:
1)使用 java.util.Collections 类的 synchronizedMap 方法包装一下 HashMap,得到线程安全的 HashMap,其原理就是对所有的修改操作都加上 synchronized。方法如下:
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) 2)使用线程安全的 Hashtable 类代替,该类在对数据操作的时候都会上锁,也就是加上 synchronized。
3)使用线程安全的 ConcurrentHashMap 类代替,该类在 JDK 1.7 和 JDK 1.8 的底层原理有所不同,JDK 1.7 采用数组 + 链表存储数据,使用分段锁 Segment 保证线程安全;JDK 1.8 采用数组 + 链表/红黑树存储数据,使用 CAS + synchronized 保证线程安全。
synchronizedMap 具体是怎么实现线程安全的?
一般我们会这样使用 synchronizedMap 方法来创建一个线程安全的 Map:
Map m = Collections.synchronizedMap(new HashMap(...));Collections 中的这个静态方法 synchronizedMap 其实是创建了一个内部类的对象,这个内部类就是 SynchronizedMap。在其内部维护了一个普通的 Map 对象以及互斥锁 mutex,如下图所示:
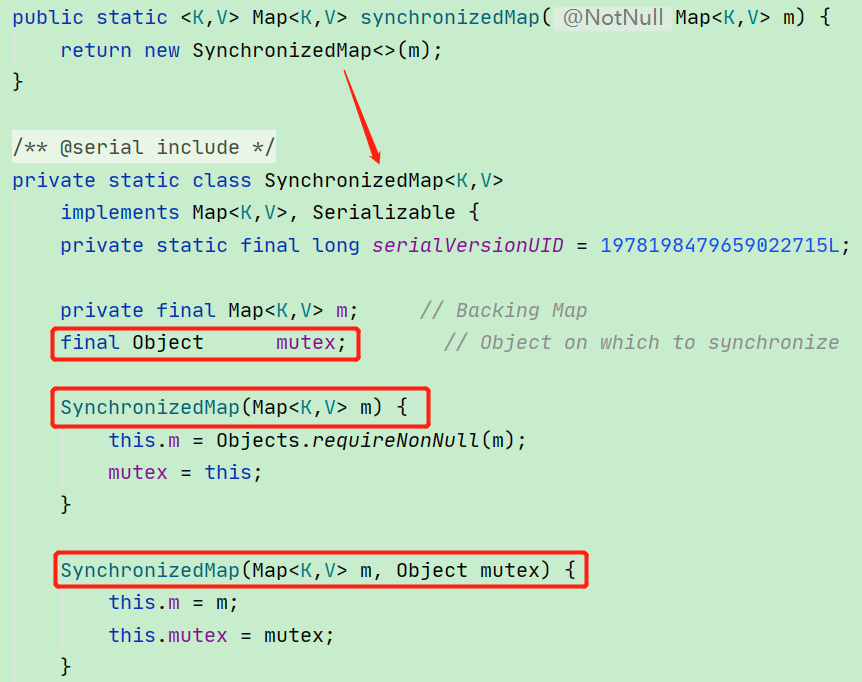
可以看到 SynchronizedMap 有两个构造函数,如果你传入了互斥锁 mutex 参数,就使用我们自己传入的互斥锁。如果没有传入,则将互斥锁赋值为 this,也就是将调用了该构造函数的对象作为互斥锁,即我们上面所说的 Map。
创建出 SynchronizedMap 对象之后,通过源码可以看到对于这个对象的所有操作全部都是上了悲观锁 synchronized 的:
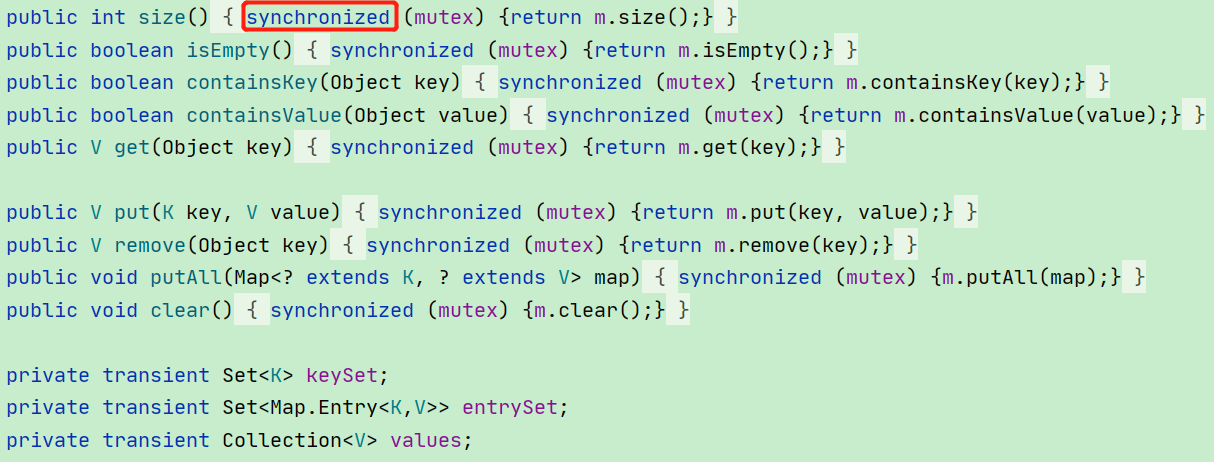
由于多个线程都共享同一把互斥锁,导致同一时刻只能有一个线程进行读写操作,而其他线程只能等待,所以虽然它支持高并发,但是并发度太低,多线程情况下性能比较低下。而且,大多数情况下,业务场景都是读多写少,多个线程之间的读操作本身其实并不冲突,所以SynchronizedMap 极大的限制了读的性能。
所以多线程并发场景我们很少使用 SynchronizedMap 。
Hashtable具体是怎么实现线程安全的?
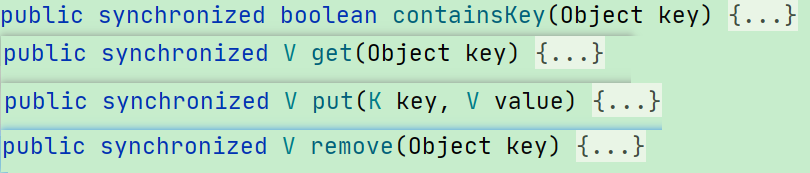
和 SynchronizedMap 一样,Hashtable 也是非常粗暴的给每个方法都加上了悲观锁 synchronized,我们随便找几个方法看看:
Hashtable 与 HashMap 的不同之处
Hashtable 是不允许 key 或 value 为 null 的,HashMap 的 key 和 value 都可以为 null 。
先解释一下 Hashtable 不支持 null key 和 null value 的原理:
1)我们 put 了一个 value 为 null 进入 Map,Hashtable 会直接抛空指针异常:

2)如果我们 put 了一个 key 为 null 进入 Map,当程序执行到下图框出来的那行代码时就会抛出空指针异常,因为 key 为 null,我们拿了一个 null 值去调用方法:

说一下 HashMap 支持 null key 和 null value 的原理:
1)HashMap 相比 Hashtable 做了一个特殊的处理,如果我们 put 进来的 key 是 null,HashMap 在计算这个 key 的 hash 值时,会直接返回 0:
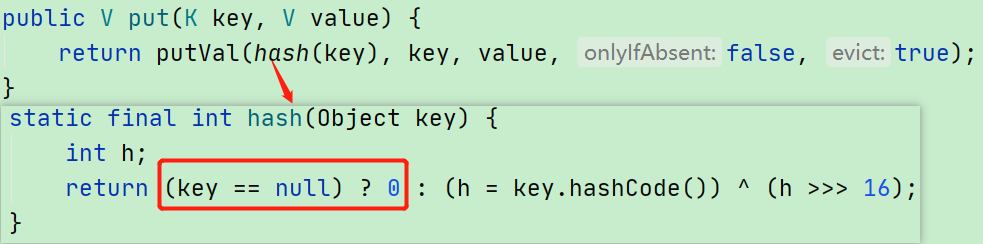
也就是说 HashMap 中 key为 null 的键值对的 hash 为 0。因此一个 HashMap 对象中只会存储一个 key 为 null 的键值对,因为它们的 hash 值都相同。
2)如果我们 put 进来的 value 是 null,由于 HashMap 的 put 方法不会对 value 是否为 null 进行校验,因此一个 HashMap 对象可以存储多个 value 为 null 的键值对。不过,这里有个小坑需要注意,我们来看看 HashMap 的 get 方法:

如果 Map 中没有查询到这个 key 的键值对,那么 get 方法就会返回 null 对象。但是我们上面刚刚说了,HashMap 里面可以存在多个 value 为 null 的键值对,也就是说,通过 get(key) 方法返回的结果为 null 有两种可能:
HashMap中不存在这个 key 对应的键值对HashMap中这个 key 对应的 value 为 null
因此,一般来说我们不能使用 get 方法来判断 HashMap 中是否存在某个 key,而应该使用 containsKey 方法。
除了 Hashtable 不允许 null key 和 null value 而 HashMap 允许以外,它俩还有以下几点不同:
1)初始化容量不同:HashMap 的初始容量为 16,Hashtable 初始容量为 11。两者的负载因子默认都是 0.75;
2)扩容机制不同:当现有容量大于总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 + 1;
3)迭代器不同:首先,Hashtable 和 HashMap 有一个相同的迭代器 Iterator,用法:
Iterator iterator = map.keySet().iterator();HashMap 的 Iterator 是 快速失败 fail-fast 的,那自然 Hashtable 的 Iterator 也是 fail-fast 的。但Hashtable 还有另外一个迭代器 Enumeration,这个迭代器是 失败安全 fail-safe 的。
1)快速失败 fail-fast:一种快速发现系统故障的机制。一旦发生异常,立即停止当前的操作,并上报给上层的系统来处理这些故障。
2)失败安全 fail-safe:在故障发生之后会维持系统继续运行。顾名思义,和 fail-fast 恰恰相反,当我们对集合的结构做出改变的时候,fail-safe 机制不会抛出异常。
引用:



